Faculty Profile - Gopala Anumanchipalli

Gopala Anumanchipalli, assistant professor of electrical engineering and computer science at UC Berkeley and adjunct professor in the neurosurgery department at UCSF, studies how humans and machines understand speech. Linguists have proposed countless models of human speech production, ranging from low-level explanations about how the shape of the vocal tract influences the sounds we produce, to higher-level theories about how we use pitch and intonation to emphasize important words in spoken dialogue. But these linguistic models have had relatively little influence on modern machine learning-based approaches to speech synthesis and recognition, such as those used in digital assistants like Siri and Alexa. Through his research, Anumanchipalli wants “to reduce this divide betweenspeech science and speech engineering.”
As a PhD student, Anumanchipalli found insights in linguistic models that helped him improve the intonation of computer-generated speech, and then took a somewhat unusual path from computer science graduate school to a neuroscience postdoc in the UCSF Chang lab. "It was not a natural transition on paper, but it was a very logical extension of my inquiry," says Anumanchipalli, adding that he wanted to understand the scientific basis of speech production.
The ultimate goal of Anumanchipalli’s postdoctoral work at UCSF was to build brain-computer interfaces for people with speech disabilities. Anumanchipalli and his colleagues successfully synthesized natural-sounding speech from recorded brain activity of speaking patients by using machine learning to decode the movements of various parts of the vocal tract responsible for producing speech sounds. Although the current model is still a proof of concept, they are working to bring their approach to patients with speech disabilities.
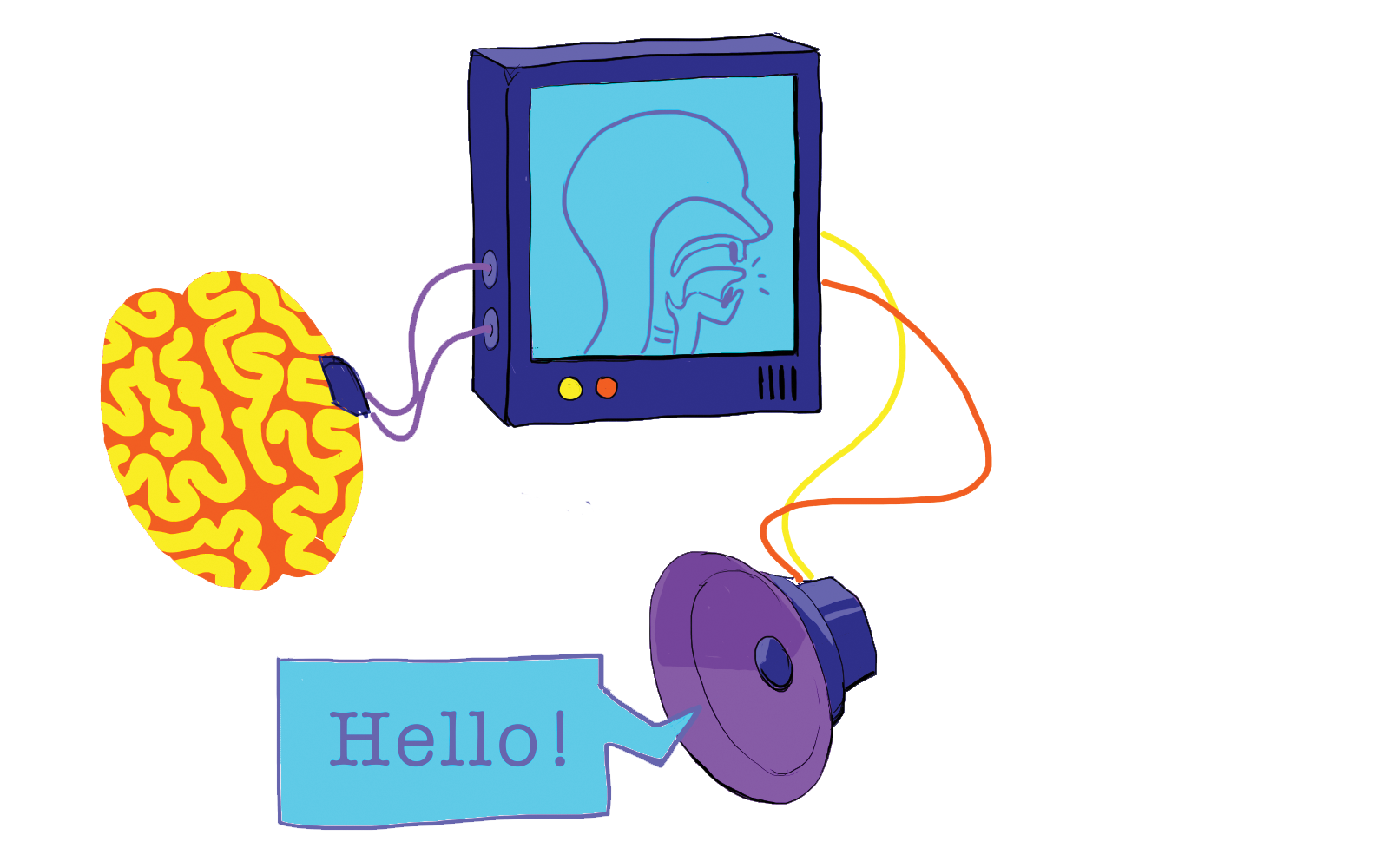
In his new role at UC Berkeley, Anumanchipalliis especially excited about researching ways that spoken language technologies can take inspiration from our scientific understanding of human speech. He explains that “speech science and engineering have both advanced, but there's not enough cross-talk between them, and I believe [more collaboration] can make objective improvements to AI systems.” To tackle this, Anumanchipalli hopes to build an interdisciplinary lab at Berkeley and looks forward to advising his first cohort of students in Fall 2021.
----- Nicholas Tomlin is a graduate student in electrical engineering and computer science.
This article is part of the Spring 2021 issue.