How the brain, graphics, and the internet sparked the AI revolution
Consider this scenario: You want to buy something at the store. You hop in your car, and you unlock your phone with Face ID. You tell it ,“Hey Google, take me to the nearest Macy’s,” and your phone navigates you to the store. After you pick what you want to buy, you point your phone at the reader. Your phone recognizes the reader and charges your card. This anecdote may seem unremarkable now, but just 10 years ago, none of this was possible. Your phone would not have identified your face, listened to your verbal cues, or used the card reader. All of these capabilities developed during the artificial intelligence (AI) revolution in the 2010s, driven by a combination of neural networks, graphics processors, and an abundance of new data.
Neural Networks Mimic the Human Brain
The AI revolution began with the rise of a class of AI algorithms known as neural networks. These algorithms, when visualized, look and behave a lot like human brains. They are made up of many intricate connections to produce a desired output, similar to the complicated connections between neurons.
When children are first learning how to read and write, a teacher might ask students to pair vocabulary words with a corresponding picture. In the same way, neural networks must be trained. Imagine we want to create a neural network that classifies images into two groups: has camel and does not have camel. First, we must teach the neural network what a camel looks like through supervised learning. We provide the network with a training set of images and explicitly tell the network which images have camels and which do not.
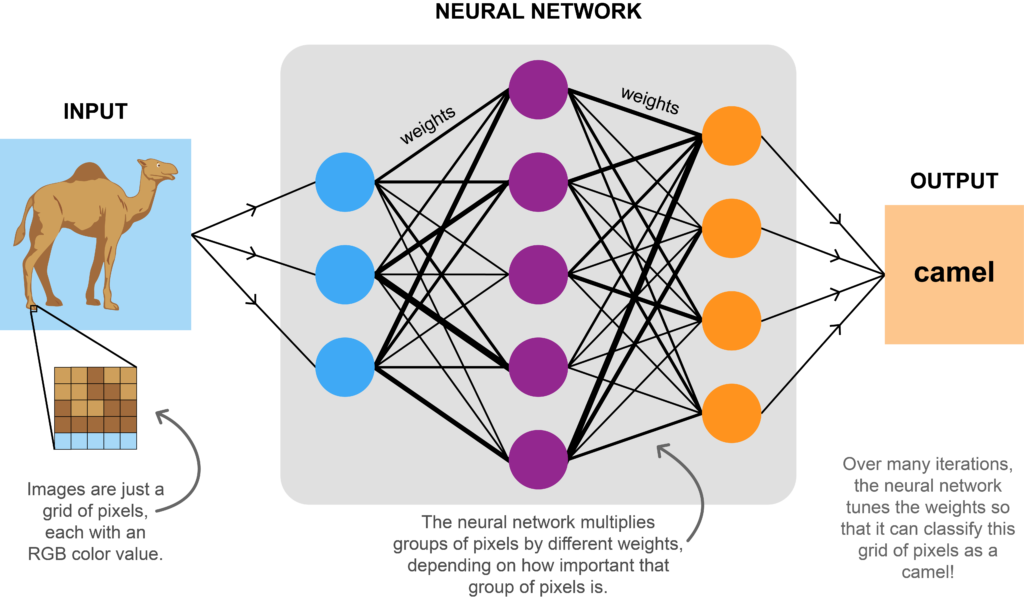 An illustration of the input, output, and internal workings of a neural network.
An illustration of the input, output, and internal workings of a neural network.
An image is fundamentally a grid of pixels. From the training images, the network learns which pixels form characteristic features of camels, such as the hump. First, it groups together a set of pixels and randomly assigns a weight that signifies how important those pixels are. After repeatedly grouping pixels and applying weights, the network can decide if the image has a camel. Based on if it was correct or not, the network tunes its weights accordingly. Over time, it learns to accurately classify images as with or without camels.
Graphics Processors Enable Efficient Neural Networks
 An illustration outlining the differences between CPUs and GPUs, and a graph showing how ImageNet’s size grew over time.
An illustration outlining the differences between CPUs and GPUs, and a graph showing how ImageNet’s size grew over time.
We know that neural networks function by repeatedly grouping pixels and multiplying them by weights. However, images can have many millions of pixels, and 20th century computer processors would routinely take days to train neural networks on these images.
Neural networks were boosted by the introduction of parallel processors in the mid-2000s. While ordinary computer processors grouped and weighted sets of pixels one by one, new parallel processors could apply weights on two to four groups of pixels at a time. However, these processors were also overkill. Parallel processors were designed to run two to four complex tasks in parallel, such as running a web browser or playing a game. In contrast, neural network tasks are simple, requiring basic steps like additions and multiplications.
What neural networks really needed were graphics processors able to run many simple tasks in parallel. For instance, graphics processors can simultaneously change every pixel in an i\mage to a different color. In the late 2000s, researchers were able to repurpose graphics processors to run neural networks, shortening the process of training neural networks from days to hours.
The Internet Provides an Abundance of Data
Even with graphics processors accelerating neural network algorithms, the data needed to train neural networks was hard to come by in the 20th century. The rise of the Internet has made data much more available now. However, just because data is out there does not mean it is easy to retrieve. In the above example, getting thousands of pictures of camels can still be a difficult task. To make this easier, in 2009, Stanford professor Fei-Fei Li and her lab developed the ImageNet database, a repository of millions of images across thousands of categories. This dataset allows AI researchers to collect thousands of images relevant to their needs.
Professor Li also began hosting an annual competition, inviting researchers to write increasingly accurate AI algorithms to classify images in ImageNet. Accuracy rates improved only slightly every year until 2012. Then Alex Krizhevsky, a graduate student at the University of Toronto, submitted a graphics processor-powered neural network to the competition in 2012. It was enormously better than the competitors and the state of the art at the time.
A combination of neural networks, graphics processors, and the Internet has powered the most recent AI revolution. However, AI is still nascent, with many open problems. Many are doing important work on reducing bias in AI algorithms. In addition, while supervised learning is popular, researchers are also studying semi-supervised learning. Here, instead of labeling all the input data, as is done in supervised learning, only a fraction of the input data is explicitly labeled. Others are developing processors specific to neural networks. From automating disease diagnosis, to discovering new materials, to developing self-driving vehicles, future research in AI will underpin technology in the future.
Alok Tripathy is a graduate student in computer science