Ash Bhat and Rohan Phadte first became aware of the issue of fake news after attending a protest at UC Berkeley against right-wing provocateur, Milo Yiannopoulos, in September 2017. They found that their experience of the protest was not at all what they saw represented on social media the next day. “The thing that was crazy was that the students were having a dance party, and what was reported on the media was that we were destroying our own school,” says Bhat. In reality, the student protest had been largely non-violent until a group of outside protesters entered the crowd and began initiating extreme acts, such as throwing fireworks and attacking people. The idea that the majority of Americans were reading reports so divorced from reality was jarring. It motivated the pair to found Robhat, a lab that uses data science and machine learning to provide insights and solutions regarding fake news.
Fake news is broadly defined as news which is untrue, but which is presented as being accurate. UC Berkeley instructional librarian, Corliss Lee, argues that fake news is also news that is deliberately untrue. “It’s not an accident,” Lee says “It’s not a little misquote. It’s deliberate and it’s usually for economic or political gain.” The abundance of fake news in the public sphere is an increasingly problematic phenomenon. From Pizzagate—a false yet viral conspiracy theory about high ranking Democratic officials being involved in a child molestation ring—to the claim that 30 thousand scientists have declared global warming a hoax, fake news can affect peoples’ beliefs and lead to potentially dangerous outcomes. Bhat compares fake news to a virus: “It’s carried by hosts, it goes viral and, at the end of the day, it can infect the way we think.” The effects of fake news have even found their way to the White House, with the Washington Post recording 4,229 false or misleading claims made by President Trump at the time of writing this piece.
In the public sphere, fake news has also been implicated in troubling changes that have taken place in our culture and institutions. Authors such as James Ball (Post-Truth: How Bullshit Conquered the World) and Matthew D’Ancona (Post-Truth: The New War on Truth and How to Fight Back) have argued that fake news has ushered in an era of “post-truth politics” where debates are conducted via highly emotive appeals at the expense of factual claims. They claim that this type of emotional discourse was at the root of the Brexit vote in the United Kingdom and the results of the 2016 US presidential election. More tangibly, a 1998 study—which has since been discredited and retracted—linking the MMR vaccine with autism is still influencing parents’ decisions to withhold immunizations from their children. This belief has led to an increase in diseases that would be easily prevented with vaccines, and increased expenditure on public information campaigns to rectify the situation. As of a decade ago, even after years of public corrections, rates of immunization in the UK have not returned to the same level as 1996, with 24 percent of mothers still erroneously considering the vaccine a greater risk than the disease it prevents and 35 to 39 percent of the public erroneously believing that there is equal evidence on both sides of the debate. Just this year, the number of measles cases in Europe has risen to an eight-year high in Europe, purportedly due to low MMR vaccination rates.
Given the impacts of fake news on politics and public health, recognizing fake news is becoming increasingly important for the general public. However, the ways in which we process information makes discerning fake news particularly challenging. For instance, we generally have trouble distinguishing between true and false information and also find fake news hard to un-learn once we have encountered it. Groups on campus, such as the UC Berkeley Library and the Public Editor Project, are working to overcome the issue by training and educating readers to read articles critically and to recognize and overcome these innate psychological tendencies. On the other hand, Bhat and Phadte are using computational algorithms to recognize and identify fake news stories for us on social media and the internet in general. These contrasting approaches raise compelling philosophical questions about the role readers and technology should play in identifying and dispelling fake news and where the line lies between protecting readers from fake news and policing free expression on the internet.
Why fake news spreads so easily
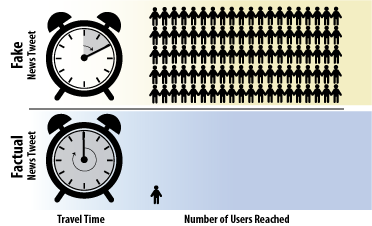 Popular fake news tweets disseminate to 100x as many people as factually correct tweets. Furthermore, fake news tweets travel 6x faster than traditional news tweets.
Popular fake news tweets disseminate to 100x as many people as factually correct tweets. Furthermore, fake news tweets travel 6x faster than traditional news tweets.
Fake news’ prevalence in the public sphere can be attributed in large part to our increased reliance on the internet for information, which has low standards for publishing and lacks a central authority to vet publications. Recent research also highlights the particularly quick and wide dissemination of fake news on social media. For instance, while factually correct tweets about the news routinely diffused to around 1,000 people on average, the top 1 percent of fake news tweets were found to routinely diffuse to up to 100,000 people. The quick spread of misinformation on social media is exacerbated by social influencers, bots, parody accounts, and cyber ghettos—areas of cyberspace where members of the same social group congregate, which results in a restricted range of views.
Preventing the spread of fake news is an especially hard problem to solve because of how difficult it is to distinguish real news from fake news. This difficulty can be explained by psychological models of how we process information. The dual processing theory, for instance, states that we have two types of processing that we draw on when we read: 1) shallow, automatic processing which leads to adequate and good-enough representations of the text and 2) effortful strategic processing that requires more executive control and mental effort. More effortful processing is more likely to be compromised by factors such as divided attention, old and young age, and sleep deprivation. Unless we are concentrating hard, we tend to process information at a relatively superficial level.
When adopting shallow processing, we make fairly automatic judgements of the truth value of information based on how familiar it is or how easily it can be understood. This gives rise to the fluency effect, where information that can be processed more fluently feels more familiar, thus more likely to be accepted as true. It is due to the fluency effect that we are more likely to judge statements as true when they are presented in a rhyming rather than a non-rhyming format or delivered in a familiar rather than unfamiliar accent.
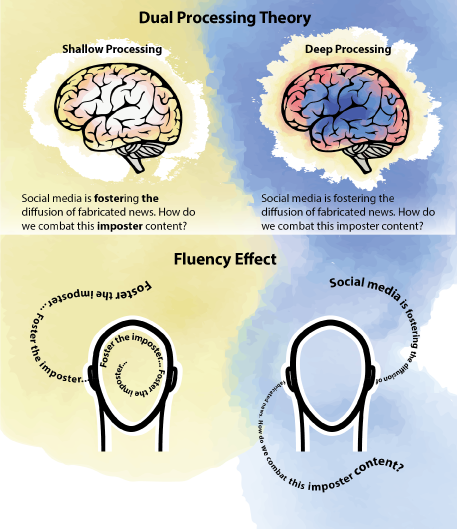 Information that is easier to understand sticks in our minds (left), while more challenging information tends to pass through (right).
Information that is easier to understand sticks in our minds (left), while more challenging information tends to pass through (right).
The fluency effect is also behind the backfire effect—a phenomenon where corrections or retractions of false information can ironically cause an increase in acceptance of the false information the retraction was meant to dispel. This effect is due to the fact that most retractions involve a repetition, which increases the familiarity of the original misinformation. An example of the backfire effect can be found in past campaigns to reduce smoking, which have been found to correlate with an increase in smoking rates. Another commonly cited example of the backfire effect is the fact that 20 to 30 percent of Americans still believe that weapons of mass destruction were discovered in Iraq after the 2003 invasion, despite proof of the non-existence of these weapons being widely reported.
In general, fake news is easy to believe and difficult to correct. Any strategies that try to alleviate its prevalence must face up to these fundamental aspects of human psychology.
Education
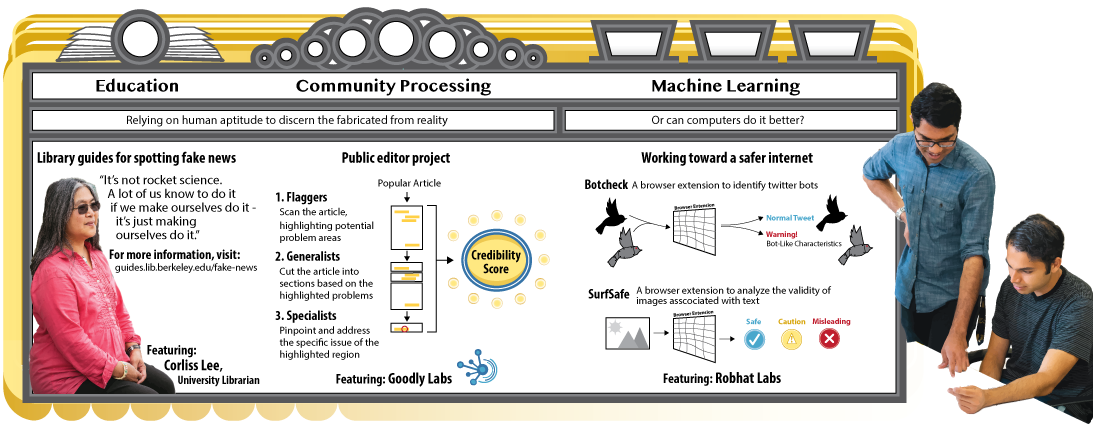
Corliss Lee uses education to help students overcome their natural tendencies to believe false information. Lee curated an online library guide called Real News/Fake, where she sets out specific ways to recognize a fake news story. Some of this advice includes reading past the headline, looking for a publication date on the story, and checking whether the source of the article produces original content or aggregates contents from other sources. In addition, Lee provides advice for evaluating the validity of sources—such as thinking about the author’s point of view—details about standard journalistic practices, and links for students to explore the issue further. “I realized this wasn’t really just about fake news,” says Lee, reflecting on the process of composing the guide. “It was about real news. You can’t have people figure out what fake news is without having them understand what real news is.” Although some of the recommendations seem obvious, she adds that it is the library’s responsibility to remind students to think before they click. “It’s not rocket science,” she says. “A lot of us know to do it if we make ourselves do it—it’s just making ourselves do it.”
Community processing of the news
One issue with a solely education driven approach to fighting fake news is that it requires an unrealistic amount of effort and time to critically assess everything you read. Other groups on campus are taking a more structured approach to the fight against fake news. The Public Editor Project, for example, is run by team of data scientists in the Berkeley Institute for Data Science. This group adopts a more community-based approach to combating low-quality information in the public sphere.
The Public Editor Project originated from a course titled Sense and Sensibilities—one of Berkeley’s Big Ideas Courses. This interdisciplinary course explores how science functions in a democracy and teaches students about scientific vocabulary and practices to help them better understand how science works. As part of a course assignment, students were asked to pick a news article and analyze how well the article communicated some of the scientific concepts covered by the course.
This assignment inspired The Public Editor Project’s team to create a web-based platform where a community of users could assess an article’s validity in a similar manner. Currently, the process works like this: a highly shared article focused on a topic like global warming or medicine is sent to a flagger, who highlights problems in the article based on pre-assigned categories like leaps in scientific reasoning or correlation versus causation concerns. When these flaggers reach a gold standard—that is, when they are evaluating articles in a similar manner to that of an expert—the article is sent on to a generalist. The generalist breaks up the article into smaller sections and sends each section on to a particular specialist who has been highly trained in one of the previously mentioned categories. The specialist then highlights the specific part of the text where they see evidence of that particular problem. At the end of the process, the different levels of assessments are then combined to produce a single credibility score for the article. “The point of a credibility score is not to say that this article is awesome or terrible. It’s to try and provide some information about how well the article does on all of these different metrics,” explains Aditya Ranganathan, a lead researcher on the team. As the project grows, he is hoping to involve as many people as possible in the process. “In the long term, my grandmother is really the person I want to target. She wakes up in the morning and does the crossword. Instead of doing the second crossword, I want her to look at two articles for us.”
While machine learning may eventually be incorporated into the project, the current focus is on human analysis of data. “There are a lot of data that can be gathered from machine learning approaches, but I also think that some of that is low-hanging fruit,” Ranganathan says. He argues that a human analysis of exactly what makes an argument unscientific will provide more nuanced information than a computational analysis could. Ranganathan, however, also acknowledges the downsides of a human-centered approach to tackling fake news. For instance, a human can’t analyze articles as fast as a computer. The project is also very much still in its development stage, relying on volunteer students and postdocs to analyze articles. “We’re hoping by the end of this year that we can look at 50 articles a day,” says Ranganthan.
Machine-based learning
While community assessments can provide a detailed breakdown of the credibility of specific articles, Bhat and Phadte argue they can use algorithms to quickly and efficiently identify the main attributes of fake news. They advocate for a machine learning approach, where computers identify patterns and make predictions from large amounts of data with minimal human intervention. One obvious advantage to a machine learning approach is the sheer amount of data that can be studied. Indeed, 50 articles a day is a world away from the 13,000 fake news articles Bhat and Phadte analyzed in a single session.
Their effort to tackle the issue of fake news began immediately after the Yiannopoulos protest, when they were surprised by the amount of attention the event was generating on Twitter. Investigating further, they found that some individual Twitter accounts that were disseminating fake news had strange tweeting patterns. “We start looking at these accounts and they’re tweeting out every minute and they’ve only been tweeting for the past day,” Bhat recounts. “We thought that this person is either crazy or not human.” Investigating further, they realized these accounts were bots.
Bot accounts are run by automated software that mimics the communication patterns of real users. Examples of harmless bots are chat bots, which are often used by companies to facilitate customer support. It is estimated that up to 30 percent of Twitter’s content is automated by bots, some of which may be used to leave supportive comments on a politician’s Twitter feed, target journalists with angry tweets, or re-tweet a politician’s post to artificially inflate their popularity. Political bots can also be used for more nefarious purposes, such as spreading political propaganda. The St. Petersburg-based Internet Research Agency, for instance, has made widespread use of bots on social media to, allegedly, manipulate public opinion in particular directions.
Seeing the problem of political propaganda bots first hand, Bhat and Phadte responded by setting up Botcheck.me, a browser extension that identifies propaganda bots and notifies the user that they are viewing an account that has the characteristics of a bot. The two started by using algorithms to scan for accounts that were tweeting at the suspiciously short time intervals of once every minute for 24 hours. Based on this single characteristic, they created an initial training set, which was then used as a basis to characterize the nature of such tweets in comparison to normal human tweeting behavior and content.
“Machine learning is so valuable because it’ll create a massive statistical model that’s looking at hundreds of different characteristics, so it can see patterns that humans just can’t,” Bhat explains. These characteristics include patterns that utilize the biographical information of the Tweeter, when the tweet was created, and specific details regarding the specific content and sentiment of each tweet. One advantage of using a machine-based approach to characterize bots, aside from the large pool of data that can be collected, is that false classifications can be fed back into the algorithm and used as additional training data to improve the model. Bhat reports, “Our algorithm has gone from 93 percent to 97 percent accuracy.”
Aside from Botcheck.me, which operates exclusively on Twitter, the pair are working on a browser extension called Surf Safe, which analyzes images associated with text on the internet and notifies the user of all the different places and contexts in which this image has previously appeared. The development of this product was spearheaded by the realization that in the most widely shared fake news of 2016, 100 percent of the articles had images, and 95 percent of these images were taken out of context.
While there may be limitations to adopting an entirely computational approach to categorize fake news, such as possible mislabeling of some more nuanced articles, Bhat and Phadte aim to categorize every existing webpage that has a picture—something that would not be achievable using a human-centered approach.
Can we truly solve fake news?
While Botcheck.me and the Public Editor Project differ in their approaches against fake news, they also differ in their views on the role of technology in addressing the problem. “The ideal aim is to make ourselves obsolete,” Ranganathan says. The primary purpose of Public Editor is to serve as an educational scaffold that gives article readers the tools to think critically about what they read. “This is as much, if not more, about training people to think critically as it is about having a number next to an article,” he says. While Bhat agrees in principle, he feels that critical thinking can only get the reader so far. “There’s just so much information that we consume these days that for us to actually sift through every piece of information and fact check, it becomes truly impossible.” Instead, he argues that technology and software are indispensable for the problem of fake news. “[Technology] created this problem,” he says. “In the same way, it should be able to indicate to us that ‘hey, there’s a warning here.’”
All approaches to “solve” fake news toe the line between protecting the public against fake news and unfairly policing the internet. Both the founders of Botcheck.me and the team behind the Public Editor Project are conscious of how their Berkeley origins may be perceived by the wider public. “We realized we’re two brown guys from Berkeley,” Bhat says, as he recounts the founding of Botcheck.me. “As a natural byproduct, people are immediately going to point fingers, so we tried to be as non-partisan and accountable as possible.” The Public Editor Project addresses the question of neutrality by requiring consensus among those reading and rating the articles for the process to proceed. Corliss Lee, however, doesn’t believe that fake news needs to be met with a politically neutral approach. “In the early 19th century, the library was into providing access to literacy for lower class working people,” she says, “and not everyone would have agreed that that was a neutral thing to do.”
These solutions also face the issue of preaching to the converted. For instance, it may be argued that those who are actively aware of fake news and seeking out information about it—either from the library guide, the Public Editor Project, Botcheck.me, or Surfsafe—are not the ones who stand to benefit the most from these resources. Phadte reflects that “Surfsafe is only as powerful as the community that uses it. That being said, we’re pretty confident that fake news is a problem that people care about
Solutions to fake news may be technological, educational, or community-based in nature. However, the success of all these strategies rests on whether they will be accepted and adopted by those who perpetuate and believe in fake news at the expense of factual reality. It begs the question of whether any of these strategies will ever able to achieve the same popularity, reach and virality as the phenomenon of fake news itself.
 Corliss Lee, University Librarian (far left), Rohan Phadte (center), and Ash Bhat (right) of Robhat Labs
Corliss Lee, University Librarian (far left), Rohan Phadte (center), and Ash Bhat (right) of Robhat Labs
Leela Velautham is a graduate student in education.
This article was corrected on 30 January 2019 by Katie Deets
This article is part of the Fall 2018 issue.