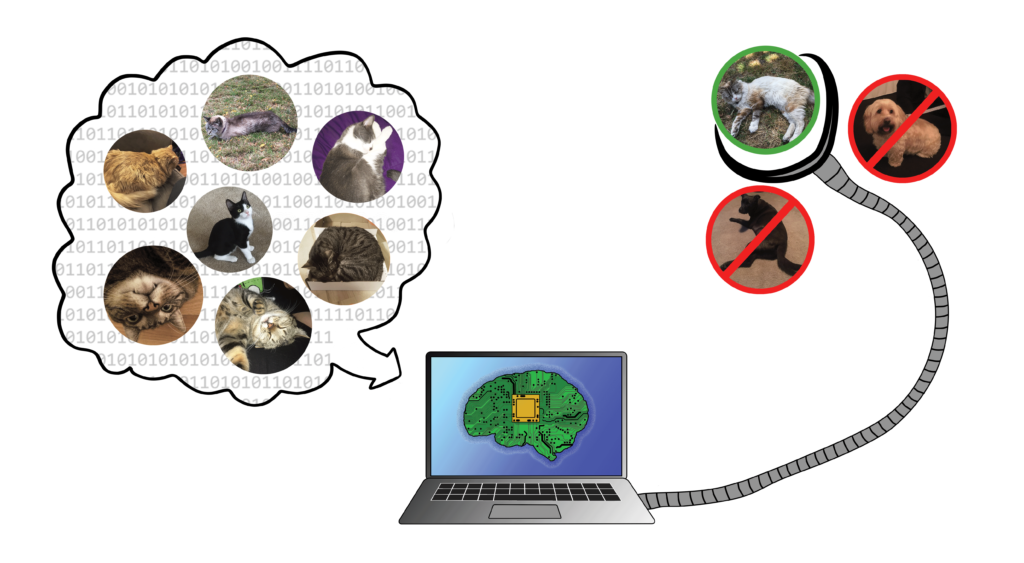
 The computer is fed a number of cat images. The computer learns what a cat looks like from the database of images. The computer is able to select the image of a cat from a set of cat and non-cat images.
The computer is fed a number of cat images. The computer learns what a cat looks like from the database of images. The computer is able to select the image of a cat from a set of cat and non-cat images.
You may find yourself Googling “machine learning” as you dive into the following articles. What you will quickly find is that the search engine you use to learn about machine learning uses the exact method you are hoping to understand. Machine learning has become highly pervasive in our society over the last several years—from product recommendations (Amazon), to self-driving cars (Google), to that time a computer beat a human at Jeopardy! in 2011 (IBM’s Watson).
The field was born several decades ago with the idea that computers can be trained to identify patterns in large data sets and make predictions based on these patterns. As an example, a computer program can be shown hundreds of different e-mails that are either spam or not spam. Over time, the program learns that words such as “singles” or “jackpot” occur frequently in spam e-mails but not in real e-mails, while the opposite is true with words like “meeting” or “potluck.” After sufficient training, the program is able to predict which emails are junk and remove them from our inboxes.
In addition to practical daily use, machine learning is proving to be highly valuable in many research environments. Scientists utilize machine learning to rapidly and efficiently analyze massive, highly complex data sets that are otherwise impossible for humans to handle. In the following articles, read how labs at UC Berkeley are using machine learning to study incredibly rare events in particle physics (“Chasing the Higgs boson”), to protect computer programs from malicious attacks (“Computational Arms Race”), and to make cells into better biofuel factories (“Pixels or DNA”).
Katie Deets is a graduate student in molecular and cell biology.
Katie Deets is a graduate student in molecular and cell biology.
This article is part of the Fall 2018 issue.