Like the planet they simulate, climate models themselves are changing. As our scientific computing technology improves, models are getting larger and more complicated in order to make better predictions. However, with greater predictive power comes greater demand for computational and electric power. In fact, scaling up the current generation of models to meet the need for reliable local-level predictions could require as much power as a city of 100,000 inhabitants. To avoid this shockingly large carbon footprint, Dr. Michael Wehner and other Lawrence Berkeley National Lab (LBL) scientists have been warning the climate science community for years that “the computational power required for extreme-scale modeling accurate enough to inform critical policy decisions requires a new breed of extreme-scale computers.”
Computer and climate scientists in the Computational Research Division at LBL and the Department of Computer Science at UC Berkeley are tackling this challenge. Digging deep into the underlying algorithms and supercomputing systems, they are putting together a new blend of hardware and software to run climate simulations that are both more accurate and more energy efficient than ever before, ensuring that the climate-change impacts of climate modeling remain negligible.
Bringing clouds into focus
A major challenge in climate simulation is capturing the effect of clouds. Clouds play an essential role in weather and climate, both by creating precipitation and by affecting the amount of radiation the planet absorbs from the sun, so accounting for cloud systems within a climate simulation is critical to ensuring overall simulation accuracy. Accurate cloud models are essential for producing reliable regional precipitation forecasts, helping people plan for how shifting rain patterns will affect supplies of food and water, alter sensitive ecosystems, and create destructive extreme weather events.
 Example of how model resolution affects accuracy of information. In this surface elevation map , a 200-km model (left) might treat Berkeley, Mount Diablo, and the Central Valley as if these locations all had the same elevation, while a 1-km model (right) would give much more precise information.
Example of how model resolution affects accuracy of information. In this surface elevation map , a 200-km model (left) might treat Berkeley, Mount Diablo, and the Central Valley as if these locations all had the same elevation, while a 1-km model (right) would give much more precise information.
Today’s climate simulations, however, do not explicitly include cloud systems. Why not? Wehner recalls how he, like many climate scientists a few years ago, felt that building cloud-system resolving models was “a great idea...but it [wasn’t] going to happen in my lifetime. It [was] too computationally expensive.”
To see how clouds increase computational cost, consider a basic ingredient in climate models: the mesh. All models are built on a “mesh” of representative points that are distributed in all directions through three-dimensional space. A running simulation computes how the values of variables like ocean temperature and wind speed, evaluated exactly at the mesh points, change over time. Anything smaller than the mesh spacing gets passed over or smeared out, so the more closely spaced the points in the mesh, the more realistic the simulation. Climate scientists are focusing their efforts on improving the horizontal mesh (i.e., east–west and north–south), which tends to be much more spread out than the vertical mesh (i.e., elevation) because distances between points on Earth can be much larger than the distance between Earth and space. In 2008, state-of-the-art global climate simulations, such as those run by LBL scientists, typically used about 13,000 points in the horizontal mesh, achieving a horizontal spacing of about 200 kilometer. But of course clouds are much smaller than 200 kilometers across. To accurately represent cloud systems, climate scientists need to refine the horizontal mesh down to a spacing of just one or two kilometers.
Such a fine mesh, however, comes with a large computational cost. In order to refine a mesh while keeping the spatial area the same, the number of points in the mesh has to increase dramatically. For example, if the horizontal mesh spacing is decreased by a factor of two, the number of representative points must go up by a factor of four, or two squared (there must be twice as many points in each direction). A two-kilometer horizontal mesh would therefore require 10,000 times as many points as a 200-kilometer mesh.
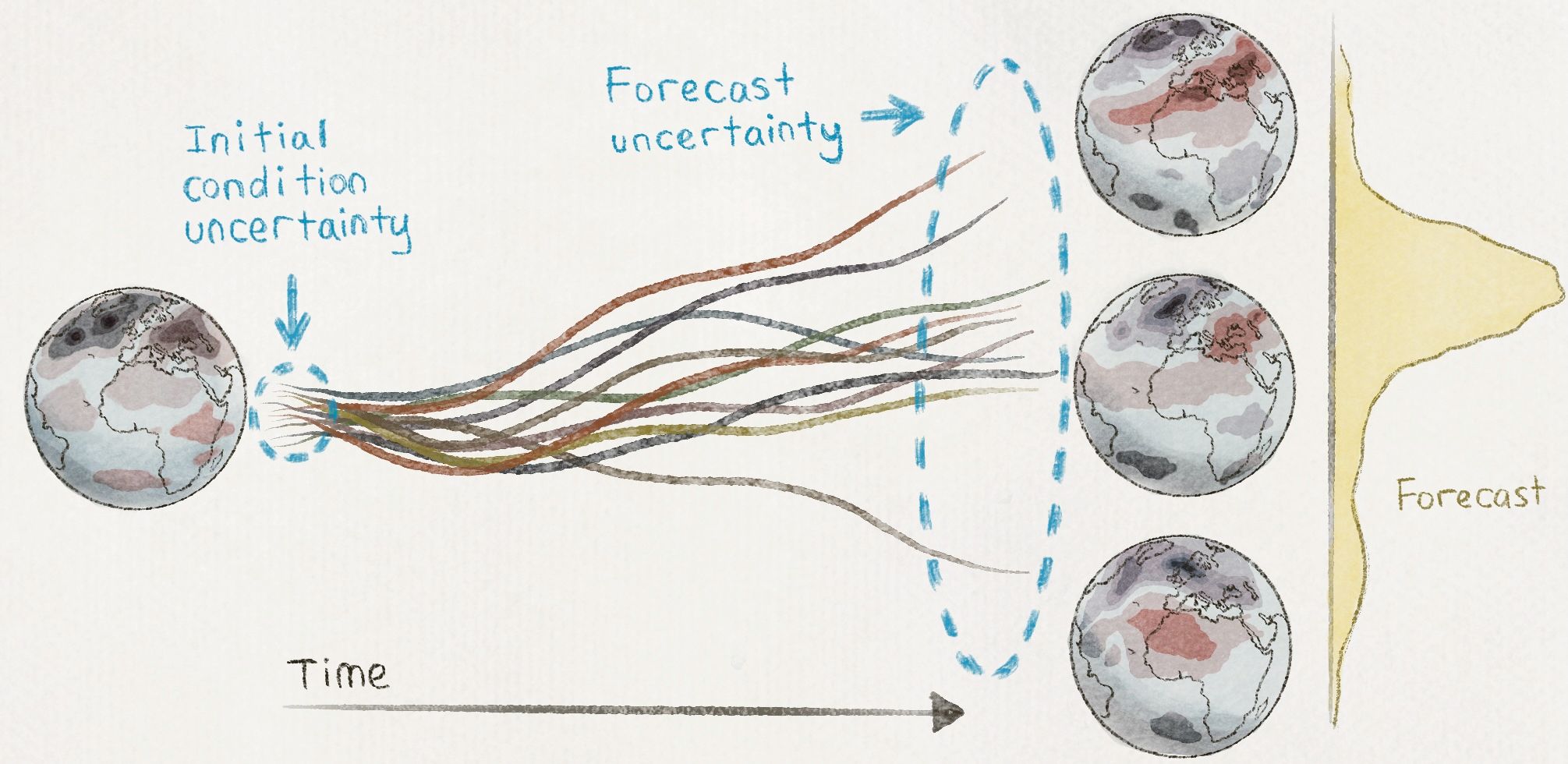
Additional mesh points, however, account for only part of the computational price. Another cost stems from how the simulation evolves in time. Climate simulations start from initial conditions (such as the present climate) and come up with predictions about future states by stepping through time, performing a new calculation at each “timestep” to predict the state of the system in small increments. It turns out that making the mesh spacing smaller while keeping the timestep size the same has potentially dire consequences.
As a simple example, consider a cloud that starts over San Francisco and moves eastward at a velocity of ten miles per hour. A simulation taking a timestep of one hour would next report the cloud ten miles east of San Francisco, a sensible answer. If instead the timestep were one day, the simulation would predict that the cloud would travel in a straight line 240 miles east to end up near Yosemite. This might be reasonable in the context of a 200-kilometer resolution model that lacks detailed information about local geography and wind patterns. But a two-kilometer resolution simulation with an overly-long timestep might try to place the cloud inside a mountain in the Sierras, a patently unphysical situation that would lead to nonsensical climate predictions.
This idea can be formulated as a strict mathematical requirement called the Courant–Friedrichs–Lewy (CFL) condition, which dictates that if mesh spacing gets smaller, the timestep size must also diminish (see Toolbox, p. 57). Specifically, halving the distance between mesh points means the simulation must take twice as many timesteps. Overall, using a mesh with half the distance between representative points will require roughly eight times the computational effort to solve. That means a simulation on a mesh with a two-kilometer spacing will take one million times as many computations as one on a mesh with a 200-kilometer spacing!
Computing the cost of computing
In 2008, Wehner decided to figure out just how much computing power he would need to run a global climate simulation with a two-kilometer mesh. “Everyone thought it would be expensive, but no one did the calculation,” Wehner explains. Specifically, he wanted to know how many computations the computer running the simulation would have to perform at the same time, a measure of performance known as flops (short for “floating point operations”) per second. Adding two numbers together is an example of a floating point operation. A modern PC can manage seven gigaflops per second, about the same computational speed as each person on Earth adding two numbers together every second. Hopper, a supercomputer at LBL, can manage one petaflop (1015 flops) per second, or roughly the same as 150,000 laptops working at the same time. The frontiers of computing today are in the so-called “exascale” range; that is, computers that can crank through 1018 (one billion billion) floating point operations in a second. Generally speaking, more flops per second means shorter simulation times, because a simulation that requires 1018 calculations could take one second on an exascale computer, rather than over 4.5 years on a laptop.
 If you have $50 million, which computing hardware should you buy?
If you have $50 million, which computing hardware should you buy?
From the CFL condition, Wehner knew that the two-kilometer model would take a million times as many floating point operations as a standard 200-kilometer model. He also knew how much “real time” the simulations should take. A useful climate model needs to be able to run 1000 times faster than real time; that is, it should take a single year to model 1000 years of global climate. Putting it all together, he estimated that a computer running a two-kilometer model would have to churn out a baseline performance of 27 petaflops per second. The peak performance would have to be even higher, in the exascale range, due to inefficiencies in how the calculations are executed.
These results were a wake-up call to the climate community. Each operation takes only a tiny amount of energy, but all those contributions add up. Running the model on existing technology would require 50–200 megawatts of power, comparable to the demand of an entire city. The cost of power alone, Wehner notes, would be hundreds of millions of dollars per year.
Communication breakdown
 LBL’s newest general-purpose supercomputer, “Edison,” uses a complex tangle of carefully-assembled network cables to pass information between its component computers.
LBL’s newest general-purpose supercomputer, “Edison,” uses a complex tangle of carefully-assembled network cables to pass information between its component computers.
There are ways to trim down this energy budget by rethinking the algorithms inside climate simulation software. This is because counting flops per second alone does not exactly measure how much energy a computational task will require. Before doing a floating point operation on two numbers, a computer has to get those numbers from somewhere—and the process of moving information around takes energy, too.
Petascale and exascale computers are built by linking together many less-powerful computers. When the component computers work together, massive amounts of information must be shuttled over the network that connects them, with concomitant huge demands for time and energy. “Minimizing arithmetic is the traditional way to optimize code, but moving data costs orders of magnitude more,” claims
James Demmel, a faculty member in the Department of Electrical Engineering and Computer Science at UC Berkeley.
Andrew Gearhart, a graduate student in EECS working with Demmel, is working on mitigating this hidden energy cost. He explains that the time and energy costs of many calculations are actually dominated by communication bandwidth; that is, the effort of moving numbers around, rather than the effort of actually adding and subtracting them. Demmel, Gearhart, and others are pioneering communication-avoiding algorithms, which organize and delegate a set of calculations so as to minimize the movement of data. Using these ideas for climate model algorithms is a critical step towards energy efficiency.
RAMPing up Green Flash
It turns out that optimal energy efficiency requires not just rethinking software, but changing the computer hardware as well. Thirty years ago, the fastest supercomputer at LBL was laboriously hand-assembled by a team that included women skilled in weaving to manage the intricate wiring. Modern supercomputers are no longer custom-built for a few specific tasks, but rather mass-produced and multifunctional. Facing the enormous computational cost of running kilometer-scale models on existing supercomputers, Wehner and his colleagues realized that greater versatility does not necessarily ensure progress. They were inspired by a seemingly unrelated piece of technology: the cell phone. Wehner points out that cell phone processors have a small set of instructions that do just one thing very efficiently. This means that they require far less power than their sophisticated supercomputer cousins, because far less energy is spent idling on tasks that never run. For a conventional supercomputer, Demmel says, this background energy demand means “spending a million dollars a year just to turn it on.” Despite this, the underlying algorithms for climate models, Wehner asserts, are probably less diverse than those that run an iPhone.
Thus the climate modelers started thinking about hardware-software co-design: building a computer from the ground up, one that would only do the tasks demanded by the specific application. Their first step was not merely to co-design, however, but to design a whole new co-design process. In the past, hardware was designed and manufactured independently of software, then tested and revised, in a cycle that took years to complete. That paradigm changed, however, with the inception of
RAMP (Research Accelerator for Multiprocessors), a project involving faculty from UC Berkeley’s EECS department as well as universities across the country. RAMP facilitates a computer simulation of a computer: researchers can create a simulation of a hardware design, and then simulate software performing a desired task on the simulated hardware. This process of design and simulation takes mere days, allowing researchers to quickly tweak a hardware design to optimal performance before actually building it.
There were still skeptics. “People said you can’t put [climate models] on a cell phone,” Wehner recalls. Nevertheless, the team worked out an exascale hardware design called Green Flash based on linking together millions of Tensilica processors (found in smartphones). Coupling custom hardware and communication-minimizing algorithms, the team predicted they could run two-kilometer resolution models with only four megawatts of power, a 12- to 40-fold reduction over Wehner’s previous estimate for a conventional model with exactly the same speed and accuracy.
No free lunch
Green Flash may sound like a computing panacea, but the adage about the impossibility of a free lunch holds as much in scientific computing as anywhere else. The radical design of an “iPod supercomputer” necessarily precludes the machine from being as versatile as a conventional supercomputer. Although other fields such as astrophysics, materials science, and high-energy physics are also eager for beefed-up computers, the narrowly-focused Green Flash design would not efficiently run the simulations these diverse disciplines employ. The earliest version of Green Flash may not even be able to run each one of the 30–50 different climate models that are used around the world.
 Michael Wehner discusses a global climate simulation with LBL climatologist Bill Collins.
Michael Wehner discusses a global climate simulation with LBL climatologist Bill Collins.
But, Wehner notes, it doesn’t have to. The design is so cost-effective, and the method so easily generalized, that with enough foresight, it would be entirely possible to design a low-power exascale computer capable of running any climate model. In fact, he envisions the need for just six or seven of these custom systems, each tailored to the specific needs of a single discipline. Such systems are already emerging. Gearhart points out that D.E. Shaw, a New York-based firm, has for years been pushing the limits of computational chemistry and biology, building custom hardware for protein folding simulations. And in late 2011, members of the original Green Flash team—John Shalf, David Donofrio, and Leonid Oliker—published a design for “Green Wave,” an energy-efficient supercomputer for seismic imaging.
A plan for disruption
Two-kilometer scale models would lead to massive improvements in both local and global forecasting. And if the simulations were efficient, researchers could run many simulations for different scenarios and compare the results. Ultimately, this would lead to a deeper understanding of the range of possible outcomes and the uncertainty in the predictions, facilitating more informed decision-making. Wehner points out that some of his collaborators on the Green Flash project have recently started working with models at four-kilometer scale, and a Japanese team has an even finer mesh up and running. Although these simulations are still preliminary, they are harbingers of the not-too-distant future of climate modeling.
Wehner acknowledges that the Green Flash project is radical, but that sometimes “you need a disruptive technology” in order to reach ambitious goals in computational science. If more disruptive technology for extreme-scale climate simulations means less disruption to the climate itself, perhaps all there is to lose is an excess of headlines about extreme weather.
This article is part of the Spring 2013 issue.